BlackHat USA 2022: Return to Sender - Detecting Kernel Exploits with eBPF

5 - 9 min read
Aug 29, 2022

Let's take a brief look at what Guillaume Fournier from Datadog presented at Blackhat USA 2022: “One of the fastest growing subsystems in the Linux Kernel is, without any doubt, eBPF (extended Berkeley Packet Filter)."
He elaborates, "Although eBPF initially targeted network monitoring and filtering use cases, its capabilities have been broadened over time. With each new kernel version, the capabilities of eBPF are getting closer to that of a kernel module with additional benefits: system safety and stability. Like any other kernel features, eBPF has introduced its fair share of kernel bugs and vulnerabilities, questioning the maturity of a solution that introduces a rich feature set but considerably increases the kernel attack surface. On the other hand, eBPF is now powering an increasing amount of endpoint protection solutions, showcasing original ideas to detect threats at runtime. Unlike many projects that aim at detecting malicious behaviors in user space, this talk focuses on how eBPF can be leveraged to detect and prevent various kernel exploitation strategies.”
Now I know you may be wondering: what exactly is eBPF? Well, let's go through it together! Given the linux kernel's unrestricted ability to monitor and manage the entire operating system, it has always been the ideal location to incorporate observability, security, and networking features. At the same time, because of its key function and high requirements for stability and security, the kernel is difficult to use when it comes to applications. Berkeley Packet Filter, or BPF for short, introduced a new interface for programs to make kernel requests alongside syscalls, making a significant modification to the old kernel model. Big name companies such as Netflix and Facebook run many BPF applications due to its capability of running new types of user-defined and kernel-mode applications. BPF is essentially a kernel and user-space observability mechanism for executing code in kernel or user space that reacts to events such as function calls, function returns, and trace points. BPF programs offer both rapid and extremely powerful and flexible ways of deep observability of what is happening in the Linux kernel or user space.
Understanding the Linux Kernel Architecture
When it comes to the Linux Kernel, there are roughly three parts to it: the user space, the linux kernel itself or the OS, and then finally we have the actual hardware. Essentially, this all works together and is wrapped in a process. Anything that is not a kernel process, such as normal apps, operates in the user space. Any code that runs within the user space has restricted hardware access and relies on kernel space code for privileged activities, such as reading and writing on the disk, or even network interaction such as sending data via a BSD or TCP socket. The Kernel space, on the other hand, contains the operating system's core. It has complete and unlimited access to all hardware, including RAM, storage, and the CPU. As we stated earlier, the kernel space is secured and only permits the most trusted programs to execute, including the kernel itself and numerous device drivers, which means code within the user space has limited access. In the image below, it basically sums up the this entire process:
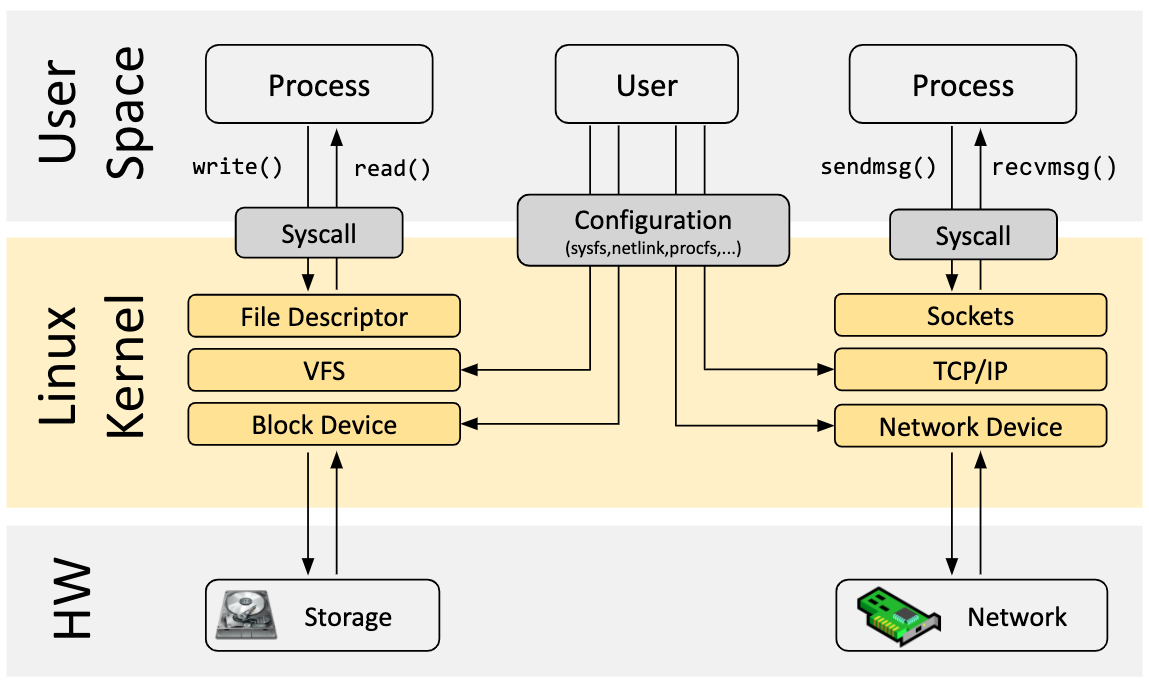
While the system call interface might be enough in some cases, developers may require complete flexibility to handle new hardware, create new programs, etc, and this requires expanding the underlying kernel without directly modifying the kernel source code. This is where eBPF comes into play.
How eBPF Works
What eBPF allows users to do is quite incredible; it allows users to take a system call and run a program that takes over on its behalf. With this in mind, it can be used to create programs for networking, debugging, tracing, firewalls, and more. eBPF was inspired by dtrace, a dynamic tracing tool available primarily for the Solaris and BSD operating systems, since there was a need for better Linux tracing capabilities. Unlike dtrace, linux at the time could not provide a layout of systems that were running hence the need to improve eBPF, giving a similar set of functionalities as dtrace. To avoid hazards such as limitless loops, eBPF applications are evaluated within the kernel. As a result, as compared to an arbitrary Linux loadable kernel module, eBPF applications represent less risk. There is an eBPF Runtime within the kernel, and the runtime ensures that these programs guarantee and meet all programmability standards. Additionally, programs are written and executed in bytecode when using eBPF. As a result, eBPF allows programmers to securely run custom bytecode within the Linux kernel without altering or adding to kernel source code, allowing applications with custom code to interact with protected hardware resources while putting the kernel at little risk.
Benefits of eBPF
eBPF can be adapted to do a variety of things, and its benefits are highlighted below:
- Performance: eBPF allows packet processing to be moved from the kernel to the user space. eBPF is also a just-in-time (JIT) compiler. eBPF is invoked after the bytecode is compiled, rather than a fresh interpretation of the bytecode for each method.
- Invasiveness is minimal: When used as a debugger, eBPF does not require the application to be stopped in order to examine its status.
- Security: Programs are essentially sandboxed, as shown in the image below, which means that kernel source code stays safe and unmodified. The verification phase guarantees that resources are not overburdened by programs that perform infinite loops. Moreover, eBPF provides a unified, robust, and user-friendly framework for tracing processes which improves both visibility and security.
- Convenience: It takes less effort to write code that hooks into kernel functions than it does to construct and maintain kernel modules.
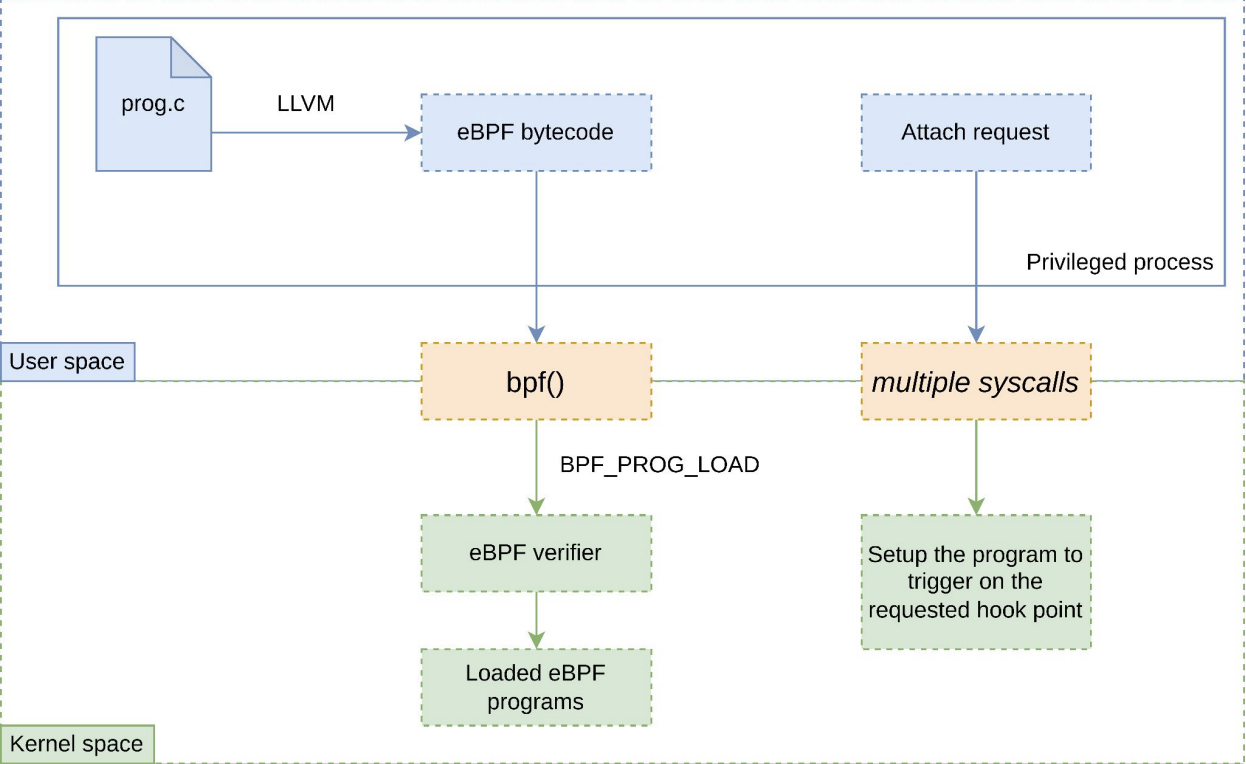
There are many reasons why people should use eBPF as listed above, but here are some reasons why you shouldn’t:
- Detecting post compromission is fighting a lost battle
- There are dozens of ways to disable an eBPF program
- eBPF can have a significant in kernel performance impact
Known Issues within the Linux Kernel
Critical CVEs are regularly discovered within the Linux Kernel. As of now, there are a recorded 3349 CVE Records for the linux kernel alone. This causes security administrators and daily users to worry about:
- Keeping up with security updates
- Deploying security patches
- Monitoring & protecting vulnerable hosts
As of now, we already have 2 vulnerabilities for the month of August with regards to the linux kernel. Firstly, we have CVE-2022-1012, which consists of a memory leak problem that was found in the TCP source port generation algorithm in the net/ipv4/tcp.c file due to the small table perturb size. This flaw could allow an attacker to leak information and can give them free rein to cause a denial of service problem or carry out a full-fledged DoS attack. The second vulnerability would be CVE-2022-1973, which consists of a use-after-free flaw that was found in the Linux kernel in the log_replay in fs/ntfs3/fslog.c file in the NTFS journal. Essentially, this flaw allows a local attacker to crash the system and leads to a kernel information leak problem. With the implementation and modification of eBPF, we can monitor kernel activity and patch zero-day attacks and vulnerabilities before they are found. For the sake of what was presented at Blackhat USA 2022, we will be discussing how to prevent the following 3 vulnerabilities with eBPF:
- Execution flow redirection
- Logic bugs
- Post compromise kernel runtime alteration
DataDogs Solution: KRIe
Kernel Runtime Integrity with eBPF is an Open-Source, Compile Once Run Everywhere tool that aims to detect Linux Kernel exploits with eBPF. KRIe is far from being a bulletproof strategy: from eBPF related limitations to post exploitation detections that might rely on a compromised kernel to emit security events, it is clear that a motivated attacker will eventually be able to bypass it. That being said, the goal of the project is to make attackers' lives harder and ultimately prevent out-of-the-box exploits from working on a vulnerable kernel.
Requirements
This project was developed on Ubuntu Focal 20.04 (Linux Kernel 5.15) and has been tested on older releases down to Ubuntu Bionic 18.04 (Linux Kernel 4.15).
- golang 1.18+
- (optional) Kernel headers are expected to be installed in lib/modules/$(uname -r), update the Makefile with their location otherwise.
- (optional) clang & llvm 14.0.6+
To best show how this tool works, the developers created two scenarios for us users:
- Scenario 1: the attacker controls the address of the next instruction executed by the kernel
- Scenario 2: the attacker is root on the machine and wants to persist its access by modifying the kernel runtime
In scenario 1, machines with SMEP & SMAP can prevent an attacker from carrying out the instruction executed in the user space, however, what about machines without SMEP & SMAP? KRIe places a kprobe and checks if the Stack pointer / Frame pointer / Instruction pointer registers point to user space memory. Remember earlier we said that KRIe is not bulletproof and attackers can find a way around the kprobe by disabling it using the commands
|
echo 0 > /sys/kernel/debug/kprobes/enabled |
Or
|
sysctl kernel.ftrace_enabled=0 |
An attacker can also disable a kprobe by killing the user space process that loaded it to begin with. KRIe combats this by setting up what they call booby traps, essentially setting the Return Object Programming or ROP chain to set the instruction the attacker is trying to take over to null.
In scenario 2, the attacker could:
- Insert a rogue kernel module
- Hook syscalls to hide their tracks
- Using kprobes
- By hooking the syscall table directly
- Use BPF filters to silently capture network traffic
- Use eBPF programs to implement rootkits
KRIe combats this by:
- Monitoring All bpf() operations and insertion of BPF filters
- Kernel module load / deletion events
- K(ret)probe registration / deletion / enable / disable / disarm events
- Ptrace events
- Sysctl commands
- Execution of hooked syscalls
All syscall tables are checked periodically and KRIE is also able to detect and report when a process executes a hooked syscall whilst also locking down the execution flows in the kernel by controlling call sites at runtime. Moreover, every detection is configurable whether it be Log, Block, Kill, or Paranoid which are different detection definements.
Our Thoughts
Powerful defensive tools can be implemented with eBPF as shown with the KRIe tool however, eBPF is not really the ideal technology to detect kernel exploits. KRIe is realistically a last resort and not a bulletproof strategy but why not put that to the test! Follow along with us in our next article as we put this open-source tool through various test-environments.